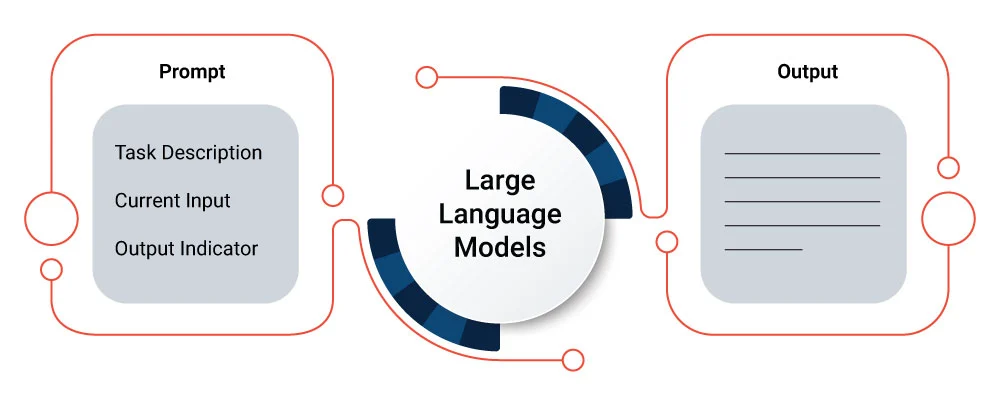
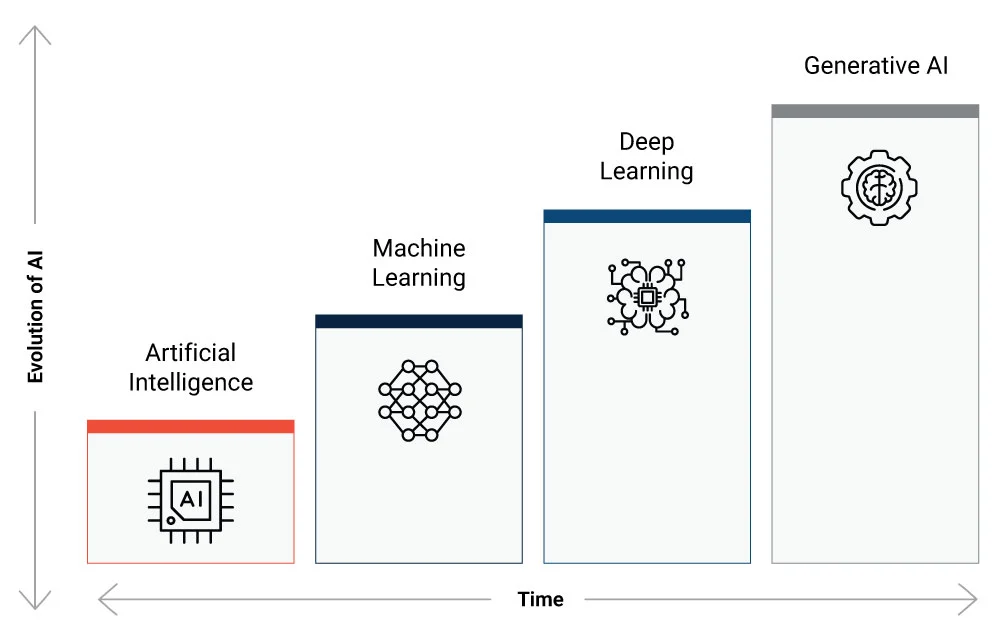
In today’s tech-driven world, terms like AI (Artificial Intelligence), ML (Machine Learning), DL (Deep Learning), and GenAI (Generative AI) have become increasingly common. These buzzwords are often used interchangeably, creating confusion about their true meanings and applications. While they share some similarities, each field has its own unique characteristics. This blog will dive into these technologies, unravel their differences, and explore how they shape our digital landscape.
What Is Artificial Intelligence (AI)?
AI is broadly defined as the ability of machines to mimic human behavior. It encompasses a broad range of techniques and approaches aimed at enabling machines to perceive, reason, learn, and make decisions. AI can be rule-based, statistical, or involve machine learning algorithms. Machine learning, Deep Learning, and Generative AI were born out of Artificial Intelligence.
Common Applications of AI are:
- Virtual Assistants: AI-powered virtual assistants like Siri, Google Assistant, and Alexa provide voice-based interaction and assistance to users.
- Healthcare Diagnosis and Imaging: AI can assist in diagnosing diseases, analyzing medical images, and predicting patient outcomes, contributing to more accurate diagnoses and personalized treatment plans.
- Virtual Reality and Augmented Reality: AI can be used to create immersive virtual and augmented reality experiences by simulating realistic environments and interactions.
- Game-playing AI: AI algorithms have been developed to play games such as chess, PubG, GTA, and poker at a superhuman level by analyzing game data and making predictions about the outcomes of moves.
What Is Machine Learning (ML)?
The term “ML” focuses on machines learning from data without the need for explicit programming. Machine Learning algorithms leverage statistical techniques to automatically detect patterns and make predictions or decisions based on historical data that they are trained on. While ML is a subset of AI, the term was coined to emphasize the importance of data-driven learning and the ability of machines to improve their performance through exposure to relevant data.
Machine Learning emerged to address some of the limitations of traditional AI systems by leveraging the power of data-driven learning. ML has proven to be highly effective in tasks like image and speech recognition, natural language processing, recommendation systems, and more.
Common Applications of ML are:
- Time Series Forecasting: ML techniques can analyze historical time series data to forecast future values or trends. This is useful in various domains, such as sales forecasting, stock market prediction, energy demand forecasting, and weather forecasting.
- Credit Scoring: ML models can be trained to predict creditworthiness based on historical data, enabling lenders to assess credit risk and make informed decisions on loan approvals and interest rates.
- Text Classification: ML models can classify text documents into predefined categories or sentiments. Applications include spam filtering, sentiment analysis, topic classification, and content categorization.
- Recommender Systems: ML algorithms are commonly used in recommender systems to provide personalized recommendations to users. These systems learn user preferences and behavior from historical data to suggest relevant products, movies, music, or content.
Scaling a machine learning model on a larger data set often compromises its accuracy. Another major drawback of ML is that humans need to manually figure out relevant features for the data based on business knowledge and some statistical analysis. ML algorithms also struggle while performing complex tasks involving high-dimensional data or intricate patterns. These limitations led to the emergence of Deep Learning (DL) as a specific branch.
What Is Deep Learning (DL)?
Deep learning plays an essential role as a separate branch within the Artificial Intelligence (AI) field due to its unique capabilities and advancements. Deep learning is defined as a machine learning technique that teaches the computer to learn from the data that is inspired by humans.
DL utilizes deep neural networks with multiple layers to learn hierarchical representations of data. It automatically extracts relevant features and eliminates manual feature engineering. DL can handle complex tasks and large-scale datasets more effectively. Despite the increased complexity and interpretability challenges, DL has shown tremendous success in various domains, including computer vision, natural language processing, and speech recognition.
Common Applications of Deep Learning are:
- Autonomous Vehicles: Deep learning lies at the core of self-driving cars. Deep neural networks are used for object detection and recognition, lane detection, and pedestrian tracking, allowing vehicles to perceive and respond to their surroundings.
- Facial Recognition: Facial recognition involves training neural networks to detect and identify human faces, enabling applications such as biometric authentication, surveillance systems, and personalized user experiences.
- Deep Learning: Deep learning models can analyze data from various sources, such as satellite imagery, weather sensors, and soil sensors. They provide valuable insights for crop management, disease detection, irrigation scheduling, and yield prediction, leading to more efficient and sustainable agricultural practices.
Deep learning is built to work on a large dataset that needs to be constantly annotated. But this process can be time-consuming and expensive, especially if done manually. DL models also lack interpretability, making it difficult to tweak the model or understand the internal architecture of the model. Furthermore, adversarial attacks can exploit vulnerabilities in deep learning models, causing them to make incorrect predictions or behave unexpectedly, raising concerns about their robustness and security in real-world applications.
These challenges have led to the emergence of Generative AI as a specific area within DL.
What Is Generative AI (GenAI)?
Generative AI, a branch of artificial intelligence and a subset of Deep Learning, focuses on creating models capable of generating new content that resemble existing data. These models aim to generate content that is indistinguishable from what might be created by humans. Generative Adversarial Networks (GANs) are popular examples of generative AI models that use deep neural networks to generate realistic content such as images, text, or even music.
Common applications of Generative AI are:
- Image Generation: Generative AI can learn from large sets of images and generate new unique images based on trained data. This tool can generate images with creativity based on prompts like human intelligence.
- Video Synthesis: Generative models can create new content by learning from existing videos. This can include tasks such as video prediction, where the model generates future frames from a sequence of input frames. It can also perform video synthesis by creating entirely new videos. Video synthesis has entertainment, special effects, and video game development applications.
- Social Media Content Generation: Generative AI can be leveraged to automate content generation for social media platforms, enabling the creation of engaging and personalized posts, captions, and visuals. By training generative models on vast amounts of social media data, such as images and text, they can generate relevant and creative content tailored to specific user preferences and trends.
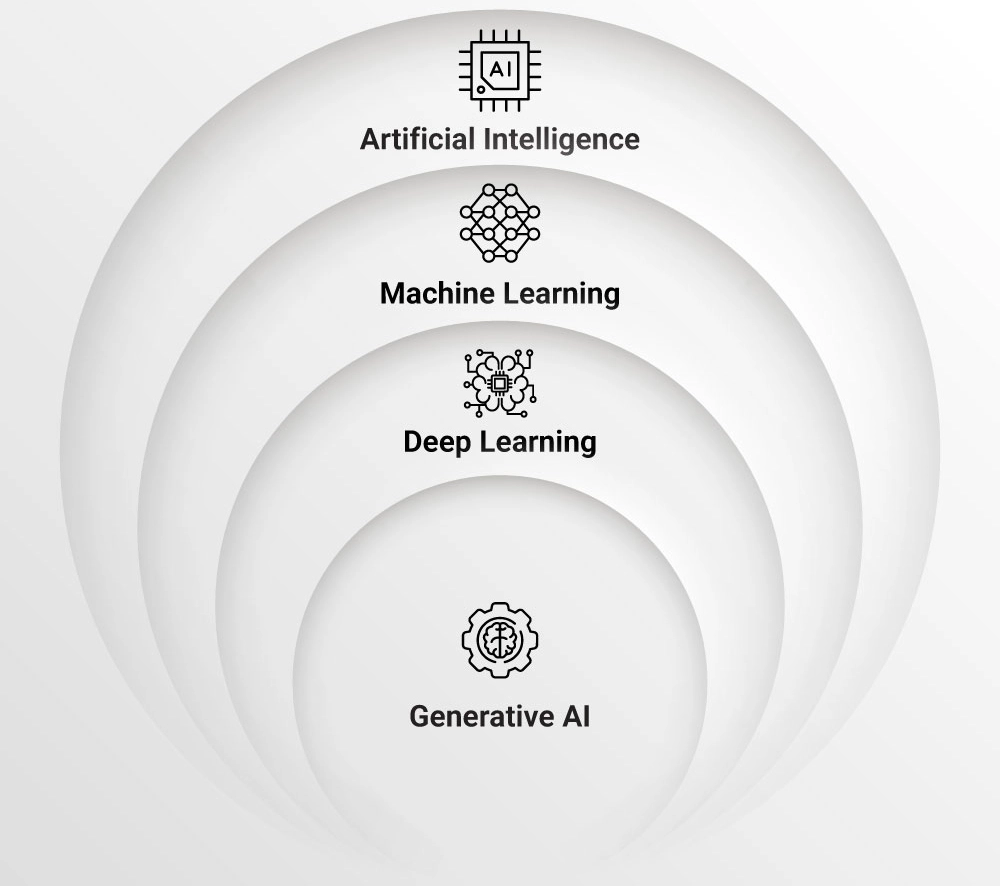
In the dynamic world of artificial intelligence, we encounter distinct approaches and techniques represented by AI, ML, DL, and Generative AI. AI serves as the broad, encompassing concept, while ML learns patterns from data, DL leverages deep neural networks for intricate pattern recognition, and Generative AI creates new content. Understanding the nuances among these concepts is vital for comprehending their functionalities and applications across various industries.
While no branch of AI can guarantee absolute accuracy, these technologies often intersect and collaborate to enhance outcomes in their respective applications. It’s important to note that while all generative AI applications fall under the umbrella of AI, the reverse is not always true; not all AI applications fall under Generative AI. The same principle applies to deep learning and ML as well.
As technology continues to evolve, our exploration and advancement of AI, ML, DL, and Generative AI will undoubtedly shape the future of intelligent systems, driving unprecedented innovation in the realm of artificial intelligence. The possibilities are limitless, and the continuous pursuit of progress will unlock new frontiers in this ever-evolving field.
About the Author

Anish Purohit is a certified Azure Data Science Associate with over 11 years of industry experience. With a strong analytical mindset, Anish excels in architecting, designing, and deploying data products using a combination of statistics and technologies. He is proficient in AL/ML/DL and has extensive knowledge of automation, having built and deployed solutions on Microsoft Azure and AWS and led and mentored teams of data engineers and scientists.