As enterprise applications rapidly shift to autonomous agentic architectures, traditional IT models can no longer scale. This comprehensive framework reveals how to choose an AI managed services provider built for a predictive, self-healing digital ecosystem. Discover the critical MSP vs traditional MSP key differences, evaluate your candidates against our 12-point AI MSP selection criteria checklist 2026, and learn the technical questions to ask an AI managed service provider’s team to secure the best IT services for mid-market scale.
With IDC forecasting that AI copilots and autonomous systems will be embedded in nearly 80% of enterprise workplace applications by the end of 2026, and a significant majority of corporate executives shifting toward agent-driven, real-time recommendations for critical decisions, the traditional IT playbook is officially obsolete. Modern technology infrastructure is no longer just a collection of servers and software. It is a living ecosystem of autonomous agents, predictive pipelines, and self-healing networks.
For CIOs and technology leaders, this shift completely redefines the procurement process. You are no longer just hiring a team to close tickets and maintain technical uptime. You are choosing a strategic partner to govern, optimize, and scale your digital core.
Learning how to choose an AI managed services provider requires an entirely new set of standards. This guide breaks down the core structural shifts in the market, outlines the definitive AI MSP selection criteria checklist 2026, and provides the exact framework needed to safeguard your enterprise infrastructure.
AI MSP vs Traditional MSP: Key Differences
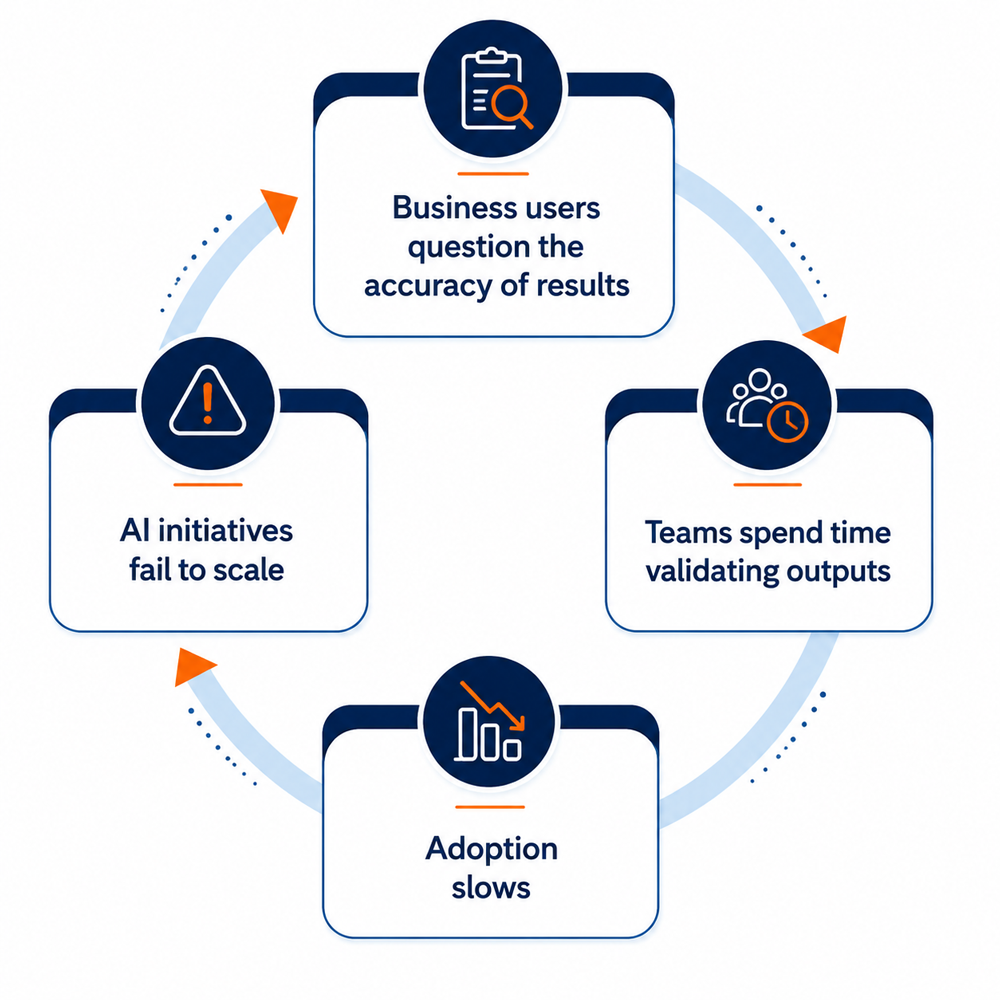
Before assessing specific vendors, it is critical to understand that a modern AI managed services provider operates on a fundamentally different architectural and commercial model than a legacy provider. Traditional managed services rely on humans where more tickets require more engineers, leading to built-in delays and reactive firefighting. An AI-driven model leverages autonomous systems to eliminate friction before it impacts the end user.
According to the Forrester AIOps Report, organizations deploying enterprise-grade AIOps platforms reduce their mean time to resolution (MTTR) by an average of 60%, and they cut overall alert noise by up to 85% within the first 12 months of deployment.
When evaluating your options, reviewing the AI MSP vs. traditional MSP key differences reveals how your enterprise will scale:
- Operational Stance: Traditional IT relies on reactive alerts after a threshold is breached. A modern AI managed services provider uses continuous machine learning models to identify telemetry anomalies, resolving infrastructure drift before a failure occurs.
- Resolution Velocity: Traditional resolution is bound by human availability, tier escalation structures, and manual documentation lookup times. An AI managed services provider delivers instantaneous resolution for tier-one and tier-two incidents via autonomous agentic AI workflows and self-healing scripts.
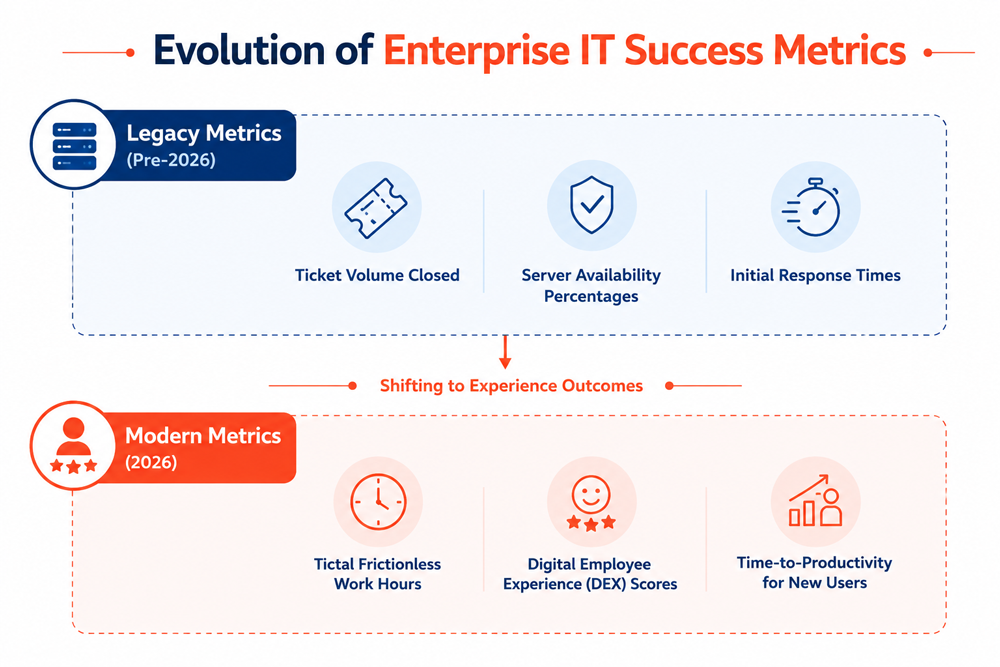
- Data Utilization: Legacy providers use siloed log aggregation primarily for historical post-mortem reviews. A mature AI managed services provider excels at continuous ingestion and feature engineering to translate operational telemetry into real-time business insights.
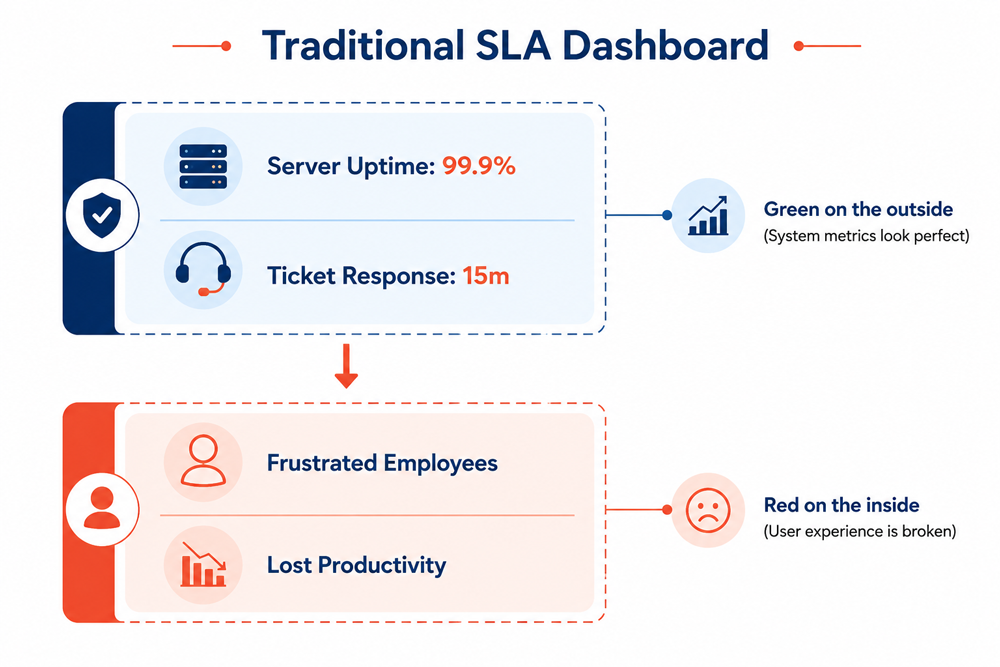
- Value Metric: Traditional models focus strictly on Service Level Agreements (SLAs) like technical uptime. An experience-driven AI managed services provider commits to Experience Level Agreements (XLAs) focused on reducing digital friction and maximizing worker productivity.
To further illustrate this industry-wide shift, Gartner forecasts that by 2029, 70% of enterprises will deploy agentic AI as part of their IT infrastructure operations, which is a massive leap from less than 5% in 2025. If you are analyzing AI MSP vs traditional MSP key differences, this mass migration toward real-world autonomous operations is the clear dividing line for your business case.
The 2026 AI MSP Selection Criteria Checklist
When shortlisting vendors for the best AI managed IT services for mid-market and enterprise ecosystems, standard procurement questionnaires fail to uncover operational realities. To ensure your partner can genuinely manage an AI-accelerated infrastructure, utilize this comprehensive AI MSP selection criteria checklist 2026 during your evaluation process.
1. Verification of AIOps Integration and Core Telemetry Ingestion
A genuine AI managed services provider does not simply layer a third-party chatbot over a legacy ticketing system. They possess a deeply integrated, AI-driven operations platform. Evaluate how the provider ingests unstructured data from your cloud environments, endpoints, and networks. The platform must be capable of correlating disparate alerts into a single, actionable incident profile automatically, reducing alert fatigue and minimizing mean time to resolution.
2. Autonomous Remediation and Self-Healing Capabilities
Ask for proof of their autonomous operational workflows. A modern provider must demonstrate established playbooks where agentic AI identifies an issue, validates the context, executes a remediation script, and verifies the resolution without human intervention. This capability should span routine tasks such as disk space optimization, service restarts, and configuration drift correction.
3. Native Support for Agentic AI Environments
As your organization deploys autonomous agents across internal departments, your IT partner must be equipped to support them. The ideal provider designs, implements, and manages solutions built on enterprise AI environments by leveraging Azure AI ML Services or AWS SageMaker. They must demonstrate clear methodologies for monitoring agentic workflows, tracking model drift, and troubleshooting multi-step autonomous tasks.
4. Advanced Feature Engineering and Data Standardization
AI systems are only as effective as the data driving them. Your partner must possess dedicated capabilities in data engineering and data preparation. They should demonstrate how they build production-ready data foundations that drive real-world performance immediately upon deployment. This includes continuous data cleaning, transformation, and ingestion pipelines that feed your analytical environments.
5. Robust Enterprise AI Governance and Ethics Frameworks
Deploying AI within enterprise IT workflows introduces complex ethical and operational risks. Your chosen partner must have a mature, codified AI governance framework. This framework must govern data lineage, model bias tracking, and microscopic transparency. It ensures that any autonomous decision made within your infrastructure is entirely auditable and compliant with corporate risk mandates.
6. Zero-Trust Security Architectures Built for AI Vectors
AI introduces entirely new security vulnerabilities, including prompt injection, data poisoning, and model inversion attacks. Your provider must protect your environment using a strict zero-trust architecture designed specifically for AI data flows. Ensure they provide continuous monitoring for your machine learning pipelines, secure your model endpoints, and maintain strict access controls over the data sets used for training and inference.
7. Strict Data Privacy and Sovereign Compliance Postures
Data sovereignty and compliance remain non-negotiable for enterprise organizations. The provider must guarantee that your corporate data is never commingled with other tenant data or utilized to train public foundational models. Review their compliance verifications for SOC 2 Type II, ISO 27001, HIPAA, or GDPR, ensuring these certifications extend directly to their AI processing environments and machine learning storage repositories.
8. Value-Based and Outcome-Aligned Pricing Models
Traditional billing models based on a flat price per device or a simple per-user fee discourage operational efficiency. When vetting AI managed services provider pricing models enterprise options, look for partners offering consumption-based or outcome-aligned pricing. Because AI drastically reduces the human time required to manage infrastructure, AI managed services provider pricing models enterprise frameworks should pass the efficiency gains back to you, allowing your budget to shift from basic maintenance to strategic innovation.
9. Proven Mid-Market Scale and Architecture Expertise
The technology needs of a mid-market organization differ significantly from those of a massive, hyper-scale global conglomerate. The best AI managed IT services for mid-market enterprises focus on agility, rapid integration, and fast time to market. Ensure the provider has a documented track record of deploying enterprise-grade AI capabilities within mid-market budget constraints, compliance parameters, and resource structures.
10. True Co-Management and Transparent Tooling Alignment
Avoid vendors who insist on locking your data inside proprietary, opaque platforms. Your partner should operate within an open, transparent tooling ecosystem that aligns directly with your internal technology stack. Whether you leverage Microsoft Azure, AWS, or hybrid environments, you must retain full visibility into the machine learning models, training pipelines, and operational dashboards used to manage your business.
11. Experience Level Agreements (XLAs) Over Legacy SLAs
Technical capability is just the entry requirement. In 2026, experience-driven IT services determine whether your IT partnership actually thrives. Traditional SLAs can show green dashboards even when your employees are actively losing time to buggy deployments or slow application responses. Your provider must commit to clear field-level XLAs that explicitly measure, track, and optimize user sentiment, digital friction, and employee productivity.
12. Strategic Transformation and Co-Innovation Roadmaps
An IT partner should not just maintain your current state. They must actively guide your digital transformation journey. Evaluate how the provider conducts regular architectural reviews and strategy sessions. They must bring proactive recommendations to the table regarding how emerging technologies, model optimizations, and automated workflows can be integrated into your business to drive continuous competitive advantage.
Questions to Ask an AI Managed Service Provider
To cut through sales presentations and uncover the true operational capabilities of a prospective vendor, it helps to understand how to choose an AI managed services provider by using targeted corporate interviews. Incorporate these specific, highly technical questions to ask AI managed service provider candidates during your RFP process:
- Operational Infrastructure: Can you demonstrate your platform executing an autonomous, multi-step remediation workflow on a P1 infrastructure incident without human intervention?
- Data Architecture: How does your platform handle unstructured data ingestion and feature engineering to ensure our predictive metrics are accurate and tailored to our environment?
- Data Protection: What specific technical controls do you implement to guarantee that our proprietary operational data is isolated and never used to train external, public models?
- Security Operations: How does your Security Operations Center identify, isolate, and mitigate AI-specific threats such as data poisoning or model-endpoint exploitation?
- Commercial Metrics: When reviewing different AI-managed services provider pricing models and enterprise options, how do your structures pass the financial and operational efficiencies of AI automation directly back to us?
- Accountability Framework: What specific methodologies, survey tools, and telemetry insights do you use to calculate and commit to experience level agreements (XLAs)?
Securing the Best AI-Managed IT Services for Mid-Market
Choosing a long-term technology partner is a major strategic decision that will define your organization’s operational velocity for years to come. For companies looking to scale efficiently, finding the best AI managed IT services for mid-market organizations means prioritizing partners who combine advanced machine learning engineering with a relentless focus on the human experience.
As a certified Microsoft Azure Expert MSP, Synoptek bridges this gap through our Managed Experience Provider (MxP™) delivery model, powered by our proprietary aiXops™ platform. Rather than managing tools in isolation, we map our operational framework directly to the AI MSP selection criteria checklist 2026, unifying predictive telemetry with real-world business outcomes.
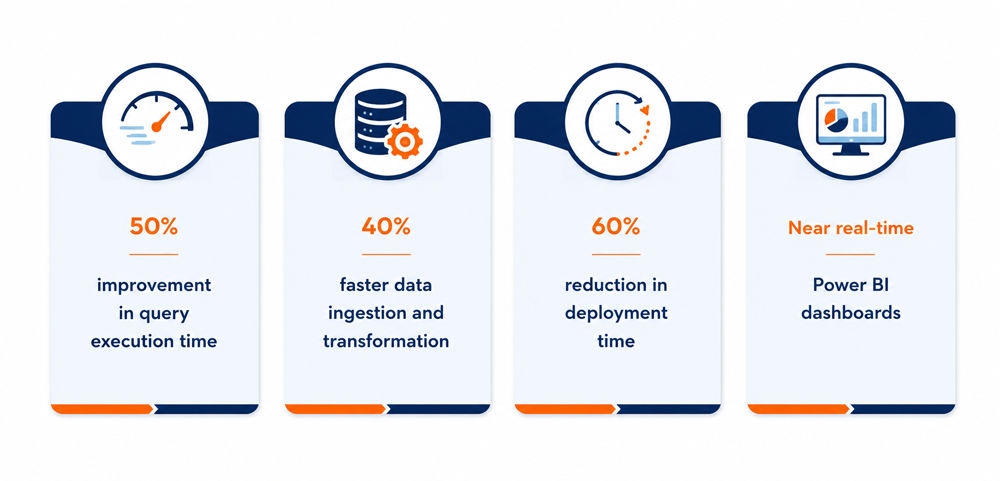
This experience-led approach delivers measurable, real-world impact. For example, when leading mental healthcare provider Sycamores needed to streamline operations across six counties supporting over 17,000 individuals, Synoptek delivered a comprehensive MxP™ transformation. By modernizing their infrastructure, upgrading clinical communication channels, and resolving technical friction, Synoptek helped reclaim over 625 staff hours and achieve more than $250,000 in operational cost savings, directly accelerating care delivery for frontline teams.
By shifting your evaluation criteria toward autonomous capabilities, robust data governance, and committed experience outcomes, you protect your infrastructure from digital friction. This comprehensive checklist approach ensures your enterprise is fully prepared to lead in an agentic, AI-driven corporate landscape.
Want to speak to our experts, book your meeting today.