December 6, 2021 · by Synoptek Team 6 min read
IT leaders want their IT operations to be proactive. But how does a struggling and reactive team move away from firefighting challenges such as routing and re-routing requests and hunting down unknown root causes causing outages to identifying challenges before they turn into problems and spending a majority of their time generating revenue, saving costs, and creating value for their business and customers?
Of course, Rome wasn’t built in a day! The journey from being a reactive IT team to one that adds value takes time and concrete planning and execution on the way. Let’s look at the high-level roadmap of how your IT operation can cover this journey.
1. Start with the foundation
It’s not the most intriguing part of the journey, but it’s absolutely the most critical! Establish a configuration management database (CMDB) that can be trusted. Your single source of truth for all CIs and assets. While there are tools to automate the population of these items and assets, it’s just as important to establish policies for governance. Define:
- Who’s going to be accountable for upkeep and changes?
- How do we prevent stale items from lingering in the database?
Everything that you’ll see and act on in the next steps will inevitably fall back on the accuracy of your CMDB. If you’re pulling data from an untrusted source, there’s simply no point in going any further. Process, policy, and governance need to be laid out at the very beginning. All these components will help capitalize on the impactful stages of the journey ahead.
2. Give your service desk some freedom
This step is about laying down the bricks for the foundation. You need to free up your Service Desk and Infrastructure/NOC teams NOW. Find a platform that your Service Desk will thank you for! ServiceNow, as an example, has made great strides alleviating the burden in a few ways:
- Driving self-service adoption through the Service Portal and Virtual Agent:
- Lowering phone and email dialogue for simple items like password reset or software access
- Auto-routing approvals for hardware/software requests
- Eliminating unnecessary actions
- Reaching the service desk when the device is approved and ready to be shipped
- Make the ordering process automated through vendor integrations
- Automating tasks for critical employee lifecycle moments (i.e., on/off-boarding, employee transition)
- Automating menial tasks with predictive intelligence and machine learning
- Route and triage incidents automatically based on historical data
- Searching for incident similarities (to propose a potential problem submission)

3. Know the infrastructure. Link the infrastructure.
Here’s where you get to capitalize on the CMDB, process and policy work from the start of our journey. Now that the make-up of your infrastructure is trusted through your populated and well-kept CMDB, it’s time to add some visibility.
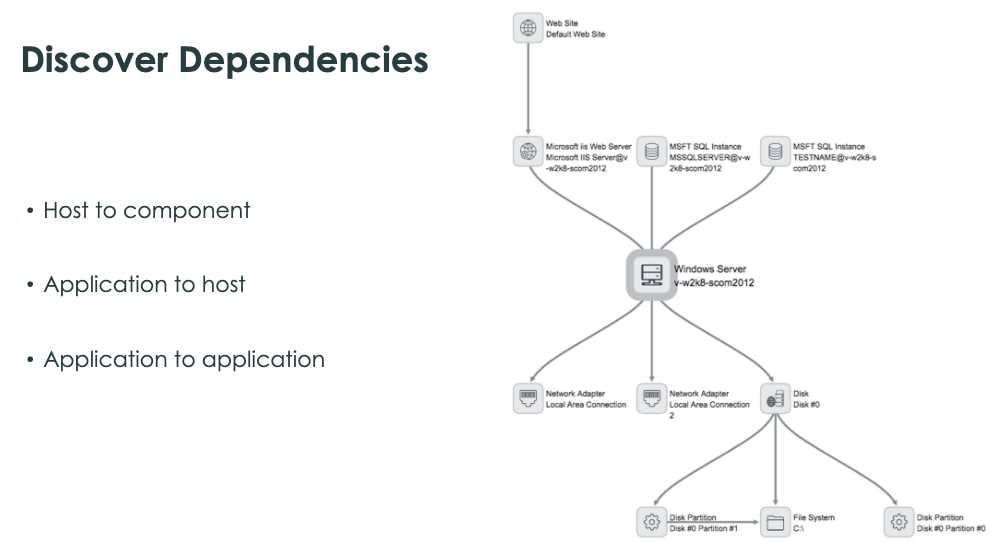
So, now you understand the dependencies within our infrastructure, but how do you get visibility into how the business services (like Email, ERP systems, CRM) are mapped?
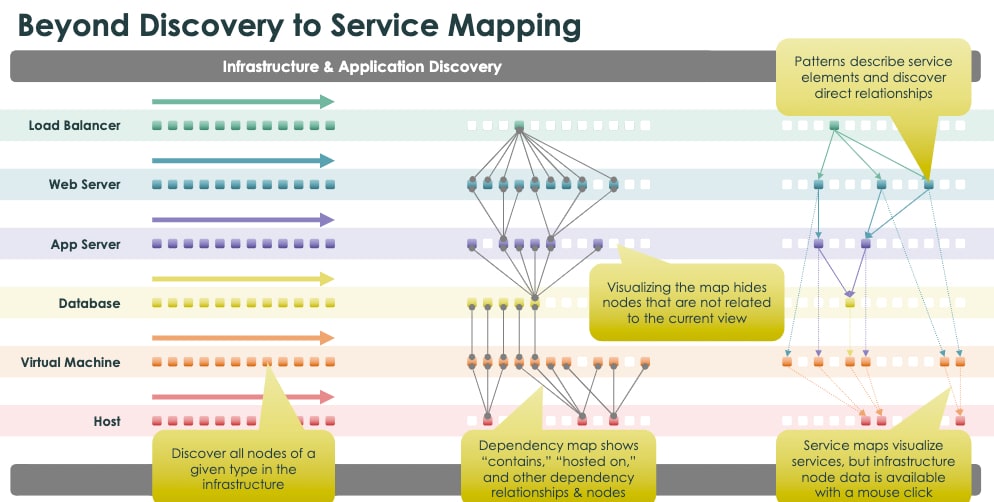
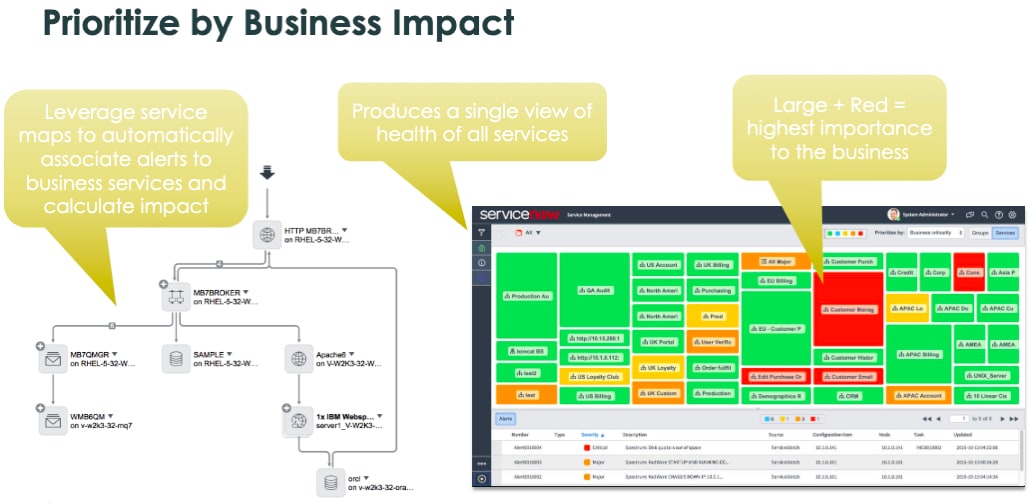
- Keep your Service owners updated on performance
- If a service outage occurs (i.e., the ERP system is down), pinpoint the root cause quickly
- ServiceNow ITOM visibility allows you to view CI’s supporting the ERP system and quickly locate the item causing the service degradation/outage
- Understand how a proposed change might impact the business service landscape
4. Start becoming proactive
Now that you have visibility, the next stage is to move toward a proactive IT operation. By the time you get to this stage, you already understand how your infrastructure truly “supports the business.” But there’s still manual work. There’s still a hint of a reactive mindset as well.
Most organizations will have monitoring tools that identify events surfacing across the environment. While that’s great already, it can be cumbersome, sifting through the noise and swivel-chairing to assign incidents. The upper echelon proactive IT teams are:
- Pulling events into one place
- Applying rules to filter out unnecessary noise
- Auto-creating and auto-assigning event-initiated incidents
- Catching and addressing red flags before they turn into problems
- Notifying impacted service owners and users before phone/email blows up
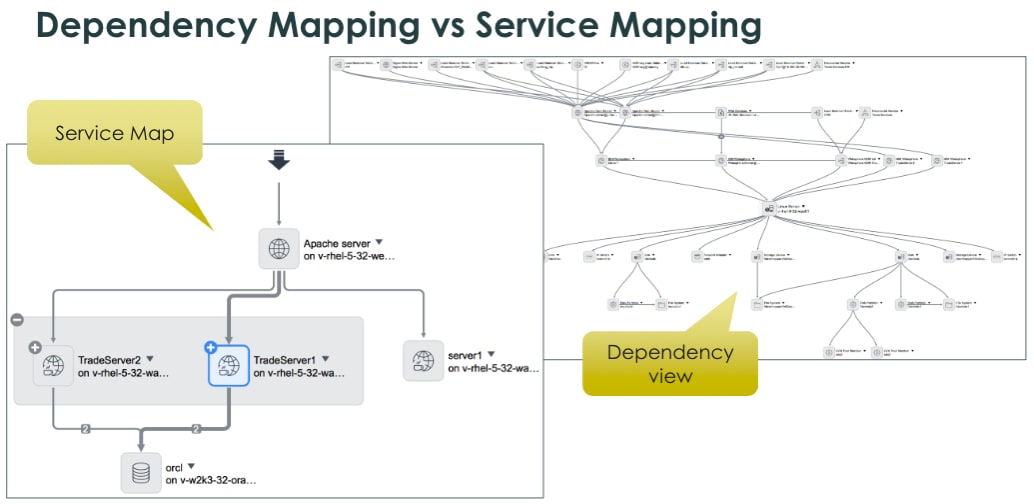
In some cases, they’re even automatically remediating certain events based on the business rules and guidelines they’ve set up.
A very similar approach can be made for SecOps teams, as they look for vulnerabilities and work to improve patch management.
5. Optimize
This is the final stage of the journey where IT can start to position itself as a major hero in the business. At this stage, they must start to focus on areas like:
- Expanding workflow improvements to other teams/BU’s
- Employee on/off-boarding and transitions
- Proactive customer support
- SecOps
- Software Asset Management
- Leveraging the CMDB to know our software spend
- Avoid compliance risk
- Kill overspend with certain unused applications
- KPI and metric alignment
- Build out a team and individual goals to support these KPIs
- Catch trends (in either direction) and adapt
- Reach KPI targets more quickly
- More effective project work
- Start understanding how to strategically use your resources
- Establish better processes for demand management
- Ensure your key initiatives and projects are aligned with business goals
That’s it! That’s all you have to do! The hardest part, though, is knowing where to start and where to go next. And hopefully, this article clearly lays that out for you.
In our clients’ most successful transitions, we’ve seen a solid 1-2 year roadmap. And most often, it has played out as we referenced above.
If you’ve had time to step away from the fire(s) for five minutes, know that Synoptek has been improving Service Management for their clients for the last two decades. We’re here to help you take that first step!